Crafting Interpreters: The map and layers (Part 1)

Virtual machines, lexers, ASTs, bytecode, runtime, JIT compilers etc. as some of the words that are introduced to us in chapter two. Chapter two unpacked a lot but in way that was as simple as possible while giving relatable examples. One highlight from the chapter was the mention of Gary Kildall. His story is a tragic one, but should be retold frequently.
The map of programming language design
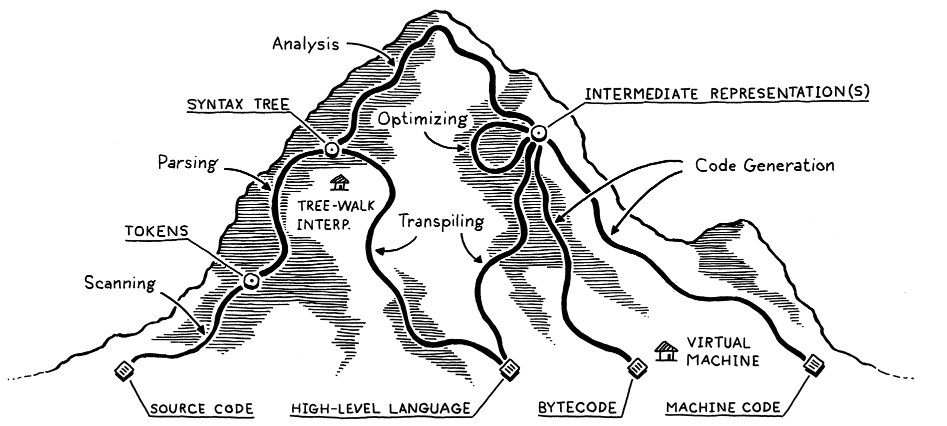
This map will be our guide in understanding the stages in the programming language design process. As I said earlier, a lot of technical terms were unpacked in this chapter, so to make it easy to understand some of them, we will follow the map paths till we reach the end. Instead of using a theoretical language to traverse the map, we will use Python. I would have used Rust, but python is much more readable and the source code of the language is easier to understand.
Traversing the map with Python
Scanning/Lexing
names = ("Banner", "Rodgers", "Stark", "Romanov")
We will start from the lower left side of the map at the source code station. From the said station, we go through the scanning path to the next station of tokens. Scanning, also called lexing, is converting this string of source code to a series of words that the would be consumed by the next stage. These words are called tokens. Some of the tokens are the keywords of the language and some other characters in the source code are discarded e.g. whitespace. So the scanning the of the line above is divided into the following tokens:
names = ( "Banner" , "Rodgers" , "Stark" , "Romanov" )
Languages have pre-defined tokens that they recognise during scanning. Python has a list of tokens that are defined in the Tokens file. Example of the tokens that Python recognises are listed below.
NAME
NUMBER
STRING
NEWLINE
INDENT
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
PLUS '+'
MINUS '-'
STAR '*'
SLASH '/'
VBAR '|'
AMPER '&'
LESS '<'
GREATER '>'
EQUAL '='
If you look closely, most of the tokens and their names are readable and easy to understand. For example, when the scanner encounters = it identifies it as the token EQUAL.
We have the following tokens from the source code line we have above:
NAME EQUAL LPAR STRING COMMA STRING COMMA STRING COMMA STRING RPAR.
Parsing
We have generated tokens after the scanning process.
On the map, we are now leaving the tokens station and heading to the syntax tree station via the parsing path.
Parsing is analysing the sequence of tokens generated and see if it conforms to the agreed grammar of the language by building a tree structure that mirrors the grammar. Grammar?! Yes, we also have grammar in these languages as well. In this stage, we take the tokens generated from the scanning process and build a tree structure mirroring the language's grammar and thus see if they are errors in the sequence of the tokens. I am sure all of us have encountered the famous SyntaxError. This is the stage where the error is generated.
To understand the parsing process, let me use an example of the English language. Let us take the sentence Thor beats Hulk. Taking the parts of speech as the tokens of the English language, thus scanning will produce the following token sequence: NOUN VERB NOUN. Parsing involves taking this sequence of tokens and compare it with the rules of the English grammar. So, we check if the English grammar has the rule NOUN VERB NOUN. This rule is found in grammar, thus the sentence is correct. However, if the sentence is beats Thor Hulk which has token sequence NOUN NOUN VERB we do not have this grammar rule for a sentence, thus we would have an error.
Back to our python example, we obtained the following token sequence:
NAME EQUAL LPAR STRING COMMA STRING COMMA STRING COMMA STRING RPAR.
Python does have a grammar which it uses during parsing. The nitty-gritty of how to interpret the grammar might need an article on its own, therefore, we will not cover it.
From the definition of parsing, we said that parsing checks if the token sequence conforms to the grammar by building a tree structure that mirrors the grammar. What is this tree structure we are talking about? Remember that the destination of parsing is the syntax tree station. The tree structure is called a parse tree or abstract syntax tree (AST). This is basically a data structure that holds the tokens generated and the values. This helps the programming language to better hold and later analyze the token sequence. The AST is generated using the grammar and it is mostly made up of nodes for each token and operation involved.
Luckily, python has a simple way of generating the AST using an inbuilt module ast. So, for the example above we obtain the following syntax tree
Module(
body=[
Assign(
targets=[
Name(id='names', ctx=Store())],
value=Tuple(
elts=[
Constant(value='Banner'),
Constant(value='Rodgers'),
Constant(value='Stark'),
Constant(value='Romanov')],
ctx=Load()))],
type_ignores=[])
A graphical representation of the AST would be :
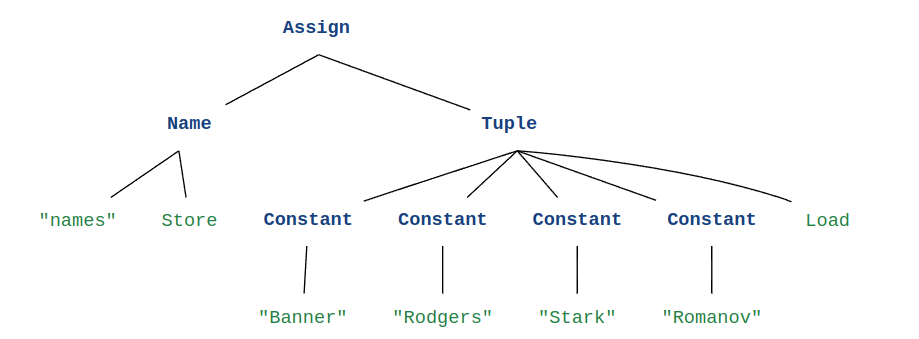
From the AST and its graphical representation, we see that the ast was able to store the assignment operation of a name node to a Tuple node. Furthermore, we see that the strings were recognized as Constant nodes with the value as the string. As you can see, the AST not only stores the tokens, but also the operations involved e.g. Assign. It is worth noting that there is no tuple token, but there is a Tuple Node in AST, this means that the grammar is used to identify a tuple from the sequence order of the provided tokens.
Phew! We are finally at the syntax tree station 🎉🎉.
Conclusion
Going back to the map, we notice that, so far we have not encountered any junction on the path. However, from the syntax tree station we have two paths to follow. This means that all languages go through the two processes i.e. Scanning and Parsing and develop an AST. Past the generation of AST is where the different languages start differing in implementation.
I will cover the other parts of the map in part two of this article.
The code to show the generated tokens and AST is found in this branch.